CSCI 431 Lecture Notes - Data Types
How do we describe a programming language?
How do we implement a programming language?
A language implementation provides a couple of very standard
capabilities:
- syntax checking:
- A program is input (usually from a source file) and its form is
checked against the syntax of the language.
- code generation:
- If the syntax of the program is in compliance with the syntax of
the language, then the text of the program is translated into the
target language (usually machine code or assembly language) and the
resulting translated form is saved in a file (the object file).
A language implementation can take two forms:
- Compiler:
- A source program is translated to machine code (or assembler
language) and this code can be executed directly on the host machine.
- Interpreter:
- A source program is translated to a new language
which is executed by another program (the interpreter).
Interpreters are often interactive, with the programming activity
carried out in an environment which is more flexible.
The structure of a translator.
- The translation process of a compiler or interpreter can be seen
in several intertwined steps.
- Tokenizer:
- The tokenizer is usually implemented as a function. When called it
reads the input stream and stops when it has read the next lexical
element - i.e., token. The tokenizer is called as needed by the
parser.
- Parser:
- The parser looks at tokens as needed and compares their order to
that required by the language (its actually easier than this sounds).
If it runs into an unexpected token, it reports an error and continues
on (in some error recovery mode) or quits.
- The parser has two other required activities which are carried
out in anticipation of error free parsing:
- Symbol Table:
- Every time the parser sees a token which is an identifier, it makes
an entry in the Symbol Table . Depending on the language
syntax, making the entry is only done if the identifier is not already
there.
- Code Generation:
- As executable program structures are encountered, appropriate code
is generated, either into a table for further processing, or into an
object file.
- This process is a simplistic view of a real translator. Often
this process takes several passes through the source file.
One pass may be used to check tokens and create a symbol table. A
second pass can involve filling in the symbol table with appropriate
attributes taken from the source code. A third pass will generate
code and the final pass do some optimization on that generated code.
Identifiers and Binding
- The most interesting tokens are identifiers.
- Identifiers are abstractions representing language entities or
constructs
- An identifier is the name of a
- variable,
- constant,
- function,
- type,
- parameter,
- or other programmer defined constructs.
- Names are for human readers of programs, good names help
understanding, bad names hinder it.
/* Can you guess what this function is doing? */
int factorial(int x, int sum) {
return x + sum * previous;
}
/* How about with these Names? */
int next_height(int height, int velocity) {
return height + velocity * ELAPSED_TIME;
}
- Every identifier must somehow be defined - either
explicitly or implicitly. (In Fortran if a variable name begins
with an `I' it is an integer variable)
Name Spaces
- Flat Name Space - in early computer languages such as COBOL,
there is only one name space in a program (so all names would be global
local static variable in C).
- Scope - portion of code in which the name is meaningful
- scope rules govern to which name space a name belongs
- Lifetime - the variable lifetime is the time between birth and death
- Note: The lifetime and scope are not always the same (consider a
local static variable in C)
- Example: C has a block-structured name space
+---------------------+----global name space
|int x; |
| |
|main (...) { |
| +----------------+------main name space
| |int x; | |
| | { | |
| | +-----------+--------block inside main name space
| | |int x; | | |
| | | | | |
| | +-----------+ | |
| | } | |
| | ... | |
| +----------------+ |
| } |
| |
|foo (...) { |
| +----------------+------foo name space
| |int x; | |
| | ... | |
| +----------------+ |
| } |
+---------------------+
Scope of Declarations and Blocks
- Typically, the scope of a declaration is from the end of the
declaration to the end of the enclosing name space or block.
- A block can be loosely defined as a program phrase that
delimits the scope of declarations that it might contain.
- For example, Pascal has blocks which are structured via
begin-end pairs, and C/C++ blocks are delimited by {
} pairs. The bindings produced inside the block override or
shadow the bindings of the outside environment.
{--- Pascal example}
procedure cat (...);
var dog : Integer; {--- override any external binding of "dog"}
begin {--- start of the block}
...
end; {--- end of the block, "dog" returns to external binding (if any)}
Free vs. Bound variables
A variable in a program block can be thought of as free if it
is not bound within the block (e.g., an access to a global variable
from within a function is an access to a free variable). Consider the
following C program fragment.
int x = 3;
foo(int y) {
x = y; /* x is free, y is bound */
}
It is important to identify free vs. bound variables since free
variables can have different bindings/meanings each time the block is
evaluated (the binding depends on something external to the function).
More about Bindings
- Every identifier has certain attributes associated with
it.
- type (i.e., simple variable, array name, function name, formal
parameter, etc.)
- type of value (i.e., integer, float, etc)
- memory location
- value
- component---binding of a data object to other data objects
- referencing environment
- potentially other information as well
- Binding is the process of associating attributes with an
identifier.
- Binding time is the time in the lifetime of an identifier
when a particular attribute is bound to it.
- Some attributes are bound at translation time (e.g., type in
Pascal), others are bound at execution time (e.g., value and
address).
- Commands and expressions cannot be interpreted in isolation, their
interpretation depends on how the identifiers are bound. E.g.
expressions like "N+1" and commands like "int N=1" are valid only if N is
declared as an integer (or maybe a float).
- It is also possible to further complicate matters given that the same
identifier can be bound to different things at different points in the
program, for example:
int X;
void foo (int X)
{
...
}
int main() {
int X;
foo(X);
...
}
Here the interpretation of X depends on the current bindings of
X. X can refer to either a global variable, a variable
local to main or a parameter of the function foo.
Environments
- An environment is a set of bindings. Each expression and
command is interpreted in a particular environment, and all
identifiers occurring in the expression or command must have bindings
in that environment.
- An environment may be thought of as a mapping from
identifiers to the entities that they denote. For example:
int X;
void foo (int X)
{
(3)
...
}
int main() {
(1)
int X;
(2)
foo(X);
...
}
The environment at point (1) is:
X -> a global integer variable
foo -> a function abstraction
At point (2):
X -> an integer variable local to main
foo -> a function abstraction
At point (3):
X -> a parameter of the function foo
foo -> a function abstraction
Static and Dynamic Binding
There are two obvious interpretations of bindings, called
static bindings and dynamic bindings. Static binding
(or static scoping) involves the function body being evaluated in the
environment of the function definition also referred to as
the lexically enclosing environment. This is what we have
seen in the examples so far. Dynamic binding (or dynamic scoping) is
slightly different in that the function body is evaluated in the
environment of the function call.
For example, consider the following Pascal code:
const s = 2;
const h = 10;
function scaled (d : Integer);
begin
scaled := d * s;
end;
function call_scaled(blah : Integer);
const s = 3;
begin
... scaled(h);
end;
begin {---main}
...
end.
If the above program uses static binding, s is evaluated at
the point of the function definition (i.e. in the function
scaled) and the value of scaled(h) is 20. If
dynamic binding is used, s is evaluated at the point of the
function call (i.e. in the function call_scaled) and the
value of scaled(h) is 30.
With static binding, we can determine the bindings of identifiers at
compile time, but with dynamic binding we must delay this until
run-time. As such, most programming languages use static binding.
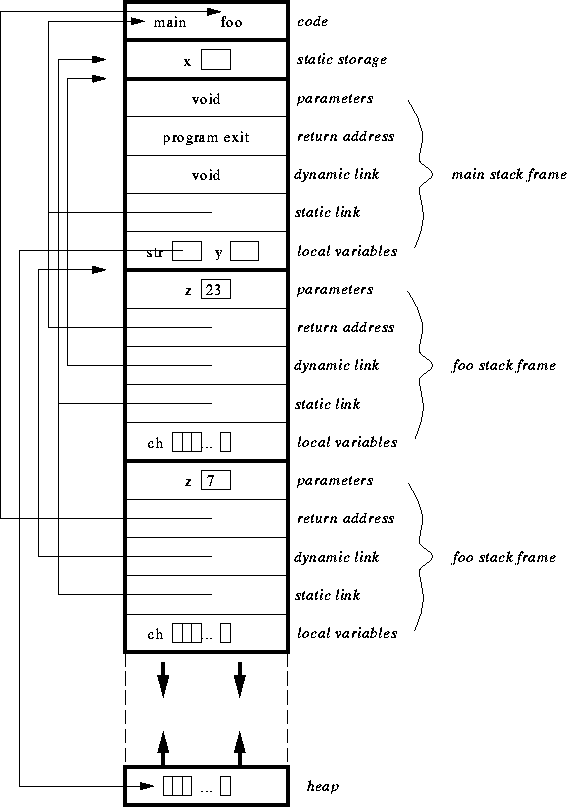
The Run-Time Stack
- storage for objects with nested lifetimes (such as function parameters
and local variable)
- very useful in recursion
- central concept is the stack frame (also called activation
record)
- visual depiction of a frame:
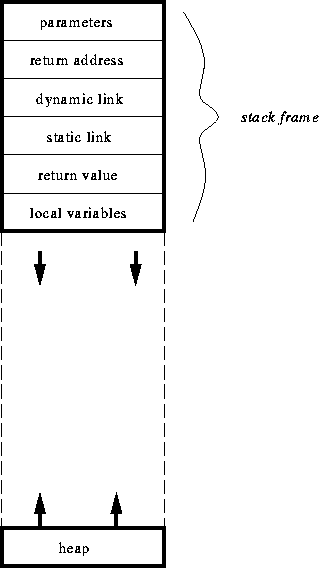
- parameters: function parameters
- return address: where to begin execution when function terminates
- dynamic link: pointer to caller's stack frame
- static link: pointer to lexical parent (for nested functions)
- return value: where to put the return value
- local variables: the functions local variables
- also a local work space which is for temporary storage of results
- function is called - push stack frame
- function is exited - pop stack frame
- visual depiction of stack calls:
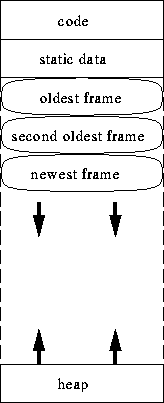
an example:
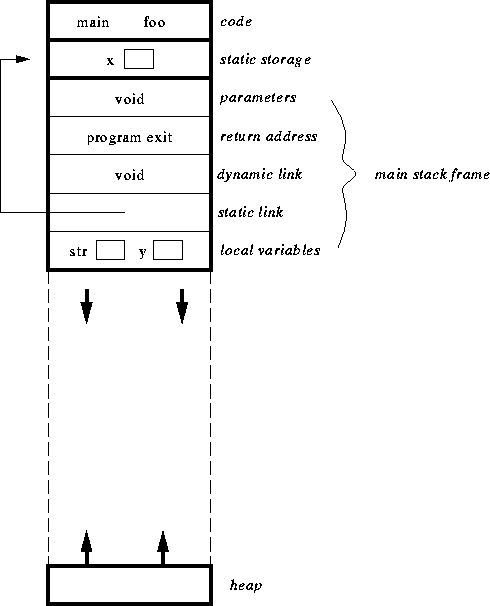
int x; /* storage for global variables */
void main() {
int y; /* stack storage for local variables */
char *str; /* stack storage for local variables */
str = malloc(100); /* allocates 100 bytes of dynamic heap storage */
y = foo(23);
free(str); /* deallocates 100 bytes of dynamic heap storage */
} /* y and str deallocated and stack frame popped */
int foo(int z) { /* z is allocated stack storage */
char ch[100]; /* ch is allocated stack storage */
if (z == 23)
foo(7);
return 3; /* z and ch are deallocated as stack frame is
popped, 3 is put on top of the stack */
}
at the start of the program:
after the first call to foo:
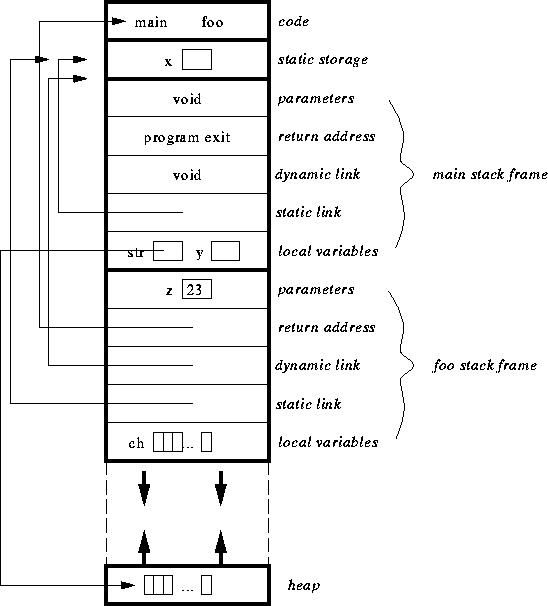
after the second call to foo:
An Aside on Cleanup
storage objects in stack storage die (are deallocated) when the
stack frame is popped.
storage objects in heap storage can be explicitly killed (as in C),
but in other languages are implicitly killed when they are no longer
referenced. For example:
/* C example */
char *str;
str = malloc(100); /* allocate a 100 byte storage object in heap storage
and put the pointer to it into str */
free(str); /* explicitly release the allocated storage object */
it is also possible to end up with pointers to dead objects. These
pointers are called dangling references. For example:
/* C example */
char *str;
str = malloc(100); /* allocate a 100 byte storage object in heap storage
and put the pointer to it into str */
free(str); /* explicitly release the allocated storage object */
*str = 'h'; /* str is now a dangling reference! This instruction
attempts to put the character 'h' into what is
pointed at by str, but str points to a storage
that is no longer allocated to the program */
Data Types
- The store or memory is a collection of data values at a
particular moment in the execution of the program.
- It is a collection of bits and can be thought of as a series of
1's and 0's
- Languages provide the user with certain basic data types
- integer
- real
- character
- boolean
- pointer
- The specification of a data type consists of:
- the attributes
- the values
- the operations
- Storage in a virtual computer can be organized into composite
data types (also known as data objects, or structured data
types), variables, and constants
Composite Data Types
A value of a composite type consists of components that may be inspected
selectively, and these components in turn may have components that may be
inspected selectively.
Features:
- occupy more than one cell
# Perl
(3, 4, 5) # creates a list with three elements
# one element in each
- computer hardware/software is geared towards efficient
manipulation of single memory locations (or cells) so typically can
selectively update single members of composite values
/* C example */
int int_array[] = (1,2,3,4,5); /* int_array has 5 items - 1,2,3,4,5 */
int_array[2] = 6; /* int_array now contains 1,2,6,4,5 */
- can composite variables grow (and occupy more cells) during run time?
Yes, it is often very useful, for example in cases where the maximum array
size is not known. We now distinguish between three different types of
arrays:
- static array - index is set and fixed at compile-time
/* Ada example */
type Real_array is array [1..10] of Real;
var a : Real_array;
a[1] := 3;
a[11] := 4; /* error - out of bounds! */
- dynamic array - index set and fixed on creation of the array variable,
this can be done in languages such as PostScript and Ada
/* Ada example */
procedure bar(m : integer) {
type Real_Array is array (Integer range <1..10>) of Real;
a : Real_Array (2..m); /* uses the current value of m */
a[4] := 3; /* maybe out of bounds! */
a[11] := 4; /* error - out of bounds! */
The advantage of this is that the array size can be set ``on the fly'', but
it is still subject to a maximum size.
- flexible array - the index is not fixed at all!
// the mighty Java
Vector any_array = new Vector(); // initially size 10 (by default)
any_array.addElement(1);
any_array.addElement(2);
...
any_array.addElement(10);
any_array.addElement(11); // out of bounds - Java doubles the size of
// the array (doubles by default)
Perl also has flexible arrays.
Implementation Issues
- The attributes for vectors and arrays are:
- upper and lower bounds
- data type of each component (it's size)
- the address of the virtual origin (element [0], or [0,0] for a
2-dimensional array)
- These attributes may be stored in a descriptor called a dope
vector
- For 1-dimensional arrays the elements are accessed using the
formula:
A[i] = V.O. + i x E.S.
- Multi-dimensional array are stored in either row-major
(the most common) or column-major order
- In row-major order the matrix is considered a vector in which each
element is a sub-vector representing one row in the original matrix.
- In column-major order the matrix is considered a vector in which each
element is a sub-vector representing one column in the original matrix.
- The access formula follows directly for the storage configuration
Type Checking
- To ensure that nonsensical operations are prevented (e.g. don't allow
multiplication of a character by a boolean; both sides of a logical
operation must be a boolean etc.)
- Type errors are a common kind of programmer error, especially when
pointers are involved.
/* C example */
void swap(int *x, int *y) {
...
}
...
int a,b;
swap(a, b); /* type mismatch error! */
When are types checked?
How are types checked - What is type equivalence?
- There are two categories of type equivalence:
- Name Equivalence: The two variables are of exactly the same name type.
typedef int new_int;
int z;
new_int y;
z = y; /* not name equivalent, so fails type check! */
- Structural Equivalence: The two variables are of the same type, if
their types are represented by the same set. That is, check to make sure
the variables have the same structure, rather than type name.
typedef int new_int;
typedef struct {
int value;
} simple_type;
typedef struct {
int value;
} another_type;
typedef struct {
int value;
char kind;
} a_third_type;
int z;
new_int x;
simple_type var_one;
another_type var_two;
a_third_type var_three;
z=x; /* OK by structure, not by name */
var_one = var_two; /* OK by structure, not by name */
var_one = var_three; /* not the same structure */
An example similar to your homework
The program:
PROGRAM MAIN(INPUT, OUTPUT) ;
PROCEDURE P(V: INTEGER) ;
VAR
X: INTEGER ;
PROCEDURE Q(V: INTEGER) ;
BEGIN
X := V ;
WRITELN("In Q -- X = ", X:2, ", V = ", V:2) ;
END ;
PROCEDURE R(V: INTEGER) ;
VAR
X: INTEGER ;
PROCEDURE S(V: INTEGER) ;
BEGIN
X := V ;
Q(V+1) ;
WRITELN("In S -- X = ", X:2, ", V = ", V:2) ;
END ;
BEGIN
X := V ;
S(V+1) ;
WRITELN("In R -- X = ", X:2, ", V = ", V:2) ;
END ;
BEGIN
X := V ;
R(V+1) ;
WRITELN("In P -- X = ", X:2, ", V = ", V:2);
IF (V < 45000) THEN
P(48048) ;
END ;
BEGIN
P(43680) ;
END .
The output of this Program:
In Q -- X = 43683, V = 43683
In S -- X = 43682, V = 43682
In R -- X = 43682, V = 43681
In P -- X = 43683, V = 43680
In Q -- X = 48051, V = 48051
In S -- X = 48050, V = 48050
In R -- X = 48050, V = 48049
In P -- X = 48051, V = 48048