CSCI 431: Formal Languages
Computation
- It is common to think of computation in mathematical terms, but
clearly mathematical applications don't cover all of the roles
computation plays.
- We could think of computation as some sort of processing
of information .
- We'll settle for a definition of computation as carrying
out a sequence of well-defined steps (a program) for the purpose of
solving a problem. (Of course, this begs the question of what is a
problem and what is a program.)
Programs
- We can think of a program as a tool for solving problems. There
are a lot of terms we could use to describe programs.
- We could think
of them as a sequence of operations for manipulating symbols or, more
simply, as some kind rule (often a very complicated rule).
- The bottom
line is that programs are something we can write down; they can be
represented as a finite sequence of symbols from some fixed (finite)
set of legal symbols.
- For example, we build C
programs with a subset of the ASCII character set and we build Java
programs from a somewhat larger character set (described as Unicode).
Problems vs. Programs
- There is a very interesting contrast between problems and the
programs that we can use to solve them. Programs are finite, while
(interesting) problems are infinite. We can use a finite program to
handle an infinite number of problem instances.
- Another interesting point about programs concerns what we get
when we run them. If we're running a program on a particular input,
it might process the data or it might run forever. If all programs
were guaranteed to always give us an answer (eventually), the world of
theoretical computer science would be a very different place.
- Programs that always give us an answer (i.e. they never just
run forever) have a special name. We call them Algorithms. We also
have the term, total functions (as opposed to partial functions).
Algorithms compute total functions.
Computational Power
- Given this notion of problems and programs, we can make a
meaningful stab at saying what computational power is. If my computer
(or programming) language lets me write programs that solve problems
that yours does not, then mine is more powerful. Or if I can write a
program on computer A that solves a particular problem that can't be
solved with any program on computer B, then
computer A has some computational power that is lacking in computer B.
- We trust that all general-purpose programming languages have the
same computational power. We'd like to believe that any problem we
can solve in Pascal, for example, can also be solved with fortran or
lisp or Prolog.
Program manipulation
- There's an idea that's very important to the study of computation
theory (which is what we are talking about right now). This is the idea
that I may want to build programs that
operate, not just on any old inputs but on other programs themselves.
- You're probably already familiar with programs that operate on other
programs. Let's see if we can think of some examples:
- Thinking about this can lead to a whole new way of thinking about
computation and formal languages. We can now have formal languages
that are made up of programs, and we can also have programs that
recognize these languages.
Compilers
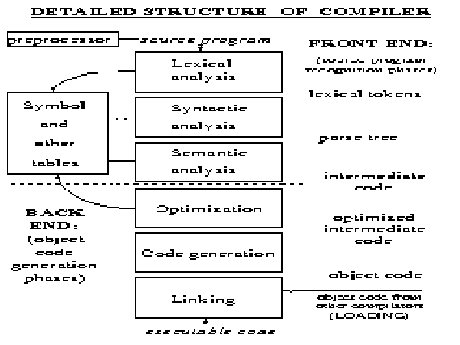
Lexical Analysis
Languages
- What is a language? Simply put, a language is a set
of strings- a very naive but essential observation.
- There are human languages, like Chinese, English and Chichewa -
an African language.
- Each language is a set of sentences, each consisting of
a string of words or phonemes, that the speakers of the language ever use
for human communication.
- There are artificial languages, e.g., programming languages like
Prolog, C/C++, Java.
- Each is a set of permissible statements, and each statement
is a string of tokens - keywords of the language or variable names defined
by a user.
- Notice that a language consists of only the legal
or grammatical strings.
- This implies that many possible strings are illegal
or ungrammatical in a specific language but they may be all
right in another one.
- How do we know which strings are grammatical
in a language and which are not---how do we recognize a language???
- To do this we need a device or mechanism that
determines the grammar of the language
- Before talk formally about a grammar, let's talk about
strings
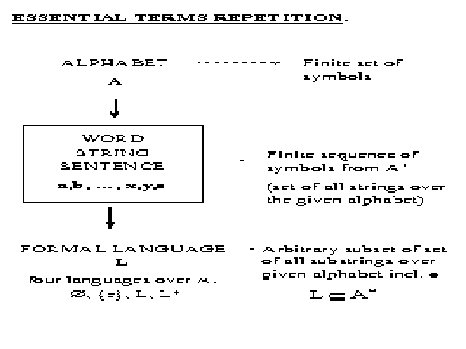
Strings
- A string is a finite sequence of some symbols.
- The symbols are atomic.
- The set of all symbols in a language is known as the
language's vocabulary or alphabet.
- Every language has a vocabulary.
- A string is a sequence of symbols in some order.
- E.g., abc is regarded as different from cba.
- A string has an length, which is the number of symbols
in the string.
- E.g., the length of abc can be denoted as |abc| = 3.
- There is an empty string e. It is length is 0.
- A* (given A is a vocabulary): the set of
all possible strings of any length on A (ie, consisting of any
number of symbols from A).
- A language on A is a subset (any subset) of
A*. But, how about a natural language (NL)?
- Is it "any subset" of its vocabulary A's A*? - No, of
course not.
- There are strong pattern or regularity in any useful
language and these are defined by the grammar or
syntax of the language.
Grammars
- A formal grammar can be described, essentially,
as a deductive system of axioms and rules of inference
that generate the sentences of a language like theorem
derivation.
- The axiom, or initial symbol is usually denoted as S
- Examples of rules are: x -> y, AB -> CDA,
S -> NP VP
- What do a rule like one of those above mean?
- It means the symbol sequence of the left-hand-side (LHS)
of a rule can be replaced by the right-hand-side (RHS) to yield new string.
e.g., the following derivation: EBABCC ==> EBCDACC.
Formal Definitions
- Terminal alphabet, denoted as VT:
- the set of symbols from which no derivation can yield any other string.
E.g., words in a language.
- Your book uses the summation symbol to represent the terminal
alphabet.
- Non-terminal alphabet, denoted VN:
- The set of symbols from which some other string can be
derived. E.g., syntactic categories in NL, like NP, V, N, etc.
- Your book uses N to represent the non-terminal alphabet.
- Formally, a grammar is a quadruple G = { VT,
VN, S, R}, where:
- VT and VN are as previously defined
- S is the start symbol
- R is the set of rules (your book uses P to represent the
set of rules).
- A notational convention:
- terminals in lowercase letters, e.g, a, b, c,
boy, girl, int, main
- non-terminal in uppercase, e.g., A, B, NP, V, P.
Recognition, generation and derivation
- Generation: derive (or yield) a new string from an old
one, initially from the initial symbol S, step by step through
applying a rule in R each step until the string in question is no
longer extendible (i.e., all symbols in the string are terminal
ones.)
- A grammar used for generation can be called a production
system
- Derivation: the process of generation. E.g.,
S ==> NP VP ==> DET
N VP ==> DET
N V NP
==> DET N
V DET ADJ N
- Actually, each rule can be understood as a derivation,
e.g., DET N is derived from NP by the rule NP -> DET N
- Recognition is the process of determining whether a
string is in a language. A string is recognized as belonging to a
language if it can be derived from the grammar for that language.
Trees
- A tree reveals (or encode) the hierarchical phrase
structure of a sentence (or a string), including the following
information:
- Hierarchical grouping of smaller constituents (or substrings)
into larger ones
- Grammatical type (category or just simply a name or label)
of a constituent;
- Some order among constituents, e.g., left-to-right word
order.
- Basics of trees
- Nodes: root, intermediate, leaves
- The yield of a tree: the sequence of leaves
- E.g., the word sequence of a NL sentence is the yield
of the sentence's phrase structure tree.
- Branches: direction, higher vs. lower nodes
- Label: non-leaf: a symbol from VN;
leaf: a symbol from VT.
- Relations: Sister(s), mother, child(s)
- Path of a node: the sequence of branches from
the node back to the root.
Grammars and Trees
- A grammar, whose rules are in the form A -> x,
generates a tree;
- Each rule is itself a tree, with the LHS as the root
and RHSs as the leaves;
- A tree for a sentence can be understood as a hierarchical
"concatenation" of trees of the rules involves in the generation
of the sentence.
Chomsky Hierarchy
- It categorizes grammars into types in terms of their generative
power. There 4 types of grammars in the Chomsky hierarchy:
- Type 0 - unrestricted rewriting systems.
-
The only "restriction" is that the left-hand side of a rule must contain
at least one non-terminal symbol, i.e., the LHS cannot be an empty string
(otherwise, it is not a grammar rule in any sense).
- Type 1 - Context sensitive grammars
- Each rule is of the form XAY
-> XBY,
- X and Y
are arbitrary strings (of symbols).
- the length of the RHS is less than or equal to that of the LHS
- Type 2 - Context free grammars
-
Rule: A ->
B
where B is any string in the V
- Type 3 - Regular grammars
- Rule: A ->
xB or A
-> x
where the first symbol on the RHS must be a terminal and may be
followed by a non-terminal
- Each language is associated with a particular computing machine,
the minimum machine required to recognize or generate strings in that
language.
- Example grammar:
- G = ({a, b}, {S, A, B}, S, R),
where
- R = { S -> e, S -> aB, S -> bA,
-
A -> a, A -> aS, A -> bAA,
-
B -> b, B -> bS, B -> aBB}
- What type of grammar is this?
Finite Automata
- Finite automata are computing machines that can recognize
languages generated by a regular grammar, these languages are called
regular languages
- An automaton is an ideal abstract computing device. It reads an
input sequence of symbols from a tape, and halts after all input
symbols are read, and then it signifies the acceptance or rejection of
the input.
- Components of an automaton
- Tape - holding the input discrete symbols;
- Reading head - scanning the input symbols in the tape;
- Control box - there is an internal state in the
box, which will be changed to next state when a symbol is read. The
next state can be a different state or the same as the current one.
- There is a designated initial state;
- There is a set of final state(s).
- The change of state from one to the next in terms of an input
symbol is known as an instruction or a transition,
represented as:
(CurrentState, InputSymbol, nextState)
- Examples:
- (q0, a, q0)
- (q0, b, q1)
- (q1, a, q1)
- (q1, b, q0)
- If q0 is a final state, an automaton with these rules would
recognizes: "a", "abb", "abab", "aabab", etc.
- Diagram Representation
- States
- Arcs (= transitions)
- Examples:
(q0, b, q1): (q0)
---b---> (q1)
- Deterministic vs. non-deterministic finite automata
- Deterministic: There is at most one arc leading out from a state
with the same symbol. That is, there are no two arcs from one state
labeled with an identical symbol in the same finite automaton.
- For any non-deterministic finite automaton, there is an
equivalent deterministic one. ie. it recognizes the same language as
the non-deterministic one does.
Formal Definition
- A deterministic finite automaton M is a quintuple <S, V,
R, Start, FS>, where
- S - a finite set of states
- V - a finite set of symbols (ie, the alphabet)
- R - a function from S x V to S (i.e, a set of transitions
to map from a <state, symbol> pair to a state)
- Start - an initial state
- FS - a set of final states
Regular Languages
- Kleene Theorem: A is a finite automaton language <==>
regular language.
The class of languages recognized by a FA is the class of regular
languages
- Conversion: (q0, b, q1): q0 ---> b q1
and then we can see q0 and q1 are non-terminals
in the correspondent regular grammar that generate the
same language as the original automaton does.
- Definition of regular languages (RLs): given an alphabet
A
- 1. The empty set if a RL;
- 2. For any string x -in- A*, {x}
is a RL;
- 3. If A and B are RLs, so are A+B (union of A and B) and
AB;
- 4. If A is a RL, so is A*;
- 5. Nothing else is a RL.
- A* - Closure or Kleene star on a set of strings A:
the set of strings formed by concatenating members of A together any
number of times (including 0) and in any order.
- Example:
{a, bb}* =
{e,a,bb,aa,abb,bb,bba,bbbb,aaa,aaabb,abba,...}
Regular expressions
- Regular languages can also be built from regular expressions
- The Definition of a regular expression: given an alphabet
A
- 1. The empty set is a regular expression;
- 2. For any symbol x -in- A, x
is a regular expression;
- 3. If e is a regular expression, then so is (e);
- 4. If e1 and e2 are regular expressions, then so are
e1 e2, e1 | e2, and e1*
- Symbols such as (, ), | and * (as well as others) may be used to
specify regular expressions
- Example: ab*c
for {ac, abc, abbc, abbbc, abbbbc, ...}
- Next time we will look at the UNIX utility egrep for specifying
and using regular expressions.
Examples
- Example 1: 0and1Even
- Example 2: a(bb)*bc
- Example 3: Binary Odd Numbers
- Example 4: 00(1|0)*11
- Example 5: Even Number of b's
- Example 6: At Most Two Consecutive b
Inadequacy of regular grammars for NL
- Examples:
- 1. the cat died.
- 2. The cat the dog chased died.
- 3. The cat the dog the rat bit chased died.
- 4. The cat the dog the rat the elephant admired bit chased died.
- They are generated by a grammar look like S
-> (NP)nVn, which is not a regular grammar.
- Next time we will look at other grammars.