- Informal (English)
- Formal: Operational, Denotational, Axiomatic
Programming Language Syntax
Ambiguous: there are flying planes.
Languages are sets of strings of characters (called sentences) from some alphabet. (Set of all syntactically correct programs).
Syntax rules determine which sentences are legal (in the language).
Syntax Criteria
- readability: self-documenting - understandable without separate
documentation
natural formats
mnemonic operator symbols
embedded comments, unrestricted length identifiers
syntax differences reflect underlying semantic differences
- writability:
concise and regular structures
unspecified declarations or operations
default typing in Fortran - side effect is undetected typo
- ease of verifiability: mathematically proven
- ease of translation: regularity of structure
Lisp - not easy to read or write, but easy to translate
Cobol- easy to read, but difficult to translate because of noise words and many ways of doing the same thing
- lack of ambiguity
Example: if if else
Languages are described in two ways:
- recognition: input the string in question and determine whether
it is or is not in the language
Like a filter: separates correct sentences from incorrect sentences
- generation: Like having a button that when pressed yields a
sentence of the language.
There is a close connection between formal generation and recognition.
(Formal) Grammars
- Used for description, parsing, analysis, etc.
- Based on recursive definition of program structure.
- Rich theory with connections to automatic parser generation, push-down automata, etc.
Chomsky Hierarchy:
- -
- Regular grammars (level 3)
- -
- Context-free grammars (level 2)
- -
- Context-sensitive grammars (level 1)
- -
- Phrase structures (level 0)
BNF (Backus-Naur Form)
John Backus (1959) (modified by Peter Naur) designed BNF (Backus Naur Form) - Same as Chomsky's context-free grammars (Is a generative technique). BNF was invented ca. 1960 and used in the formal description of Algol-60.
Metalanguage: a language used to describe another language. BNF is a metalanguage for programming languages
It is just a particular notation for grammars, in which
- Nonterminals are represented by names inside angle brackets, e.g., < expression >
- Terminals are represented by themselves, e.g., WHILE
BNF / CFG Grammar
| Nonterminal | < sentence >, < subject >, < predicate >, < verb >, < article >, < noun > |
| Terminal | the, boy, girl, ran, ate, cake |
| Start symbol | < sentence > |
| Rules | < sentence > ::= < subject > < predicate > |
| < subject > ::= < article > < noun > | |
| < predicate >::= < verb > < article > < noun > | |
| < verb > ::= ran | ate | |
| < article > ::= the | |
| < noun > ::= boy | girl | cake | |
| Operator | Replace any nonterminal by a right hand side value from any rule (==>) |
| Sentence | String of terminals derived from < sentence > by application of replacement operator |
| Examples: | |
| < sentence > ==> | < subject > < predicate > |
| ==> | < article> < noun > < predicate > |
| ==> | the < noun> < predicate > |
| ... ==> | the boy ate the cake |
| also ==> | the cake ate the boy |
| Syntax does not imply correct semantics |
Two Notations:
< A > ::= < B > | < C > d
A -> B | C d
Derivation trees:
B -> 0B | 1B | 0 | 1
B ==> 0B
==> 01B ==> 010
From derivation get parse tree
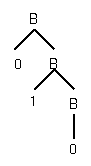
But derivation may not be unique:
S -> SS | (S) | ()
S ==> SS
==> (S)S ==> (())S ==> (())()
S ==> SS
==> S() ==> (S)() ==> (())()
and same parse tree
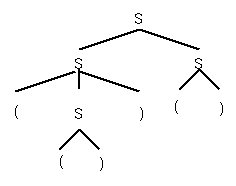
But can get 2 parse trees from same string: ()()(), each corresponds to a unique derivation:
S ==> SS ==> SSS ==> ()SS ==> ()()S ==>
()()()
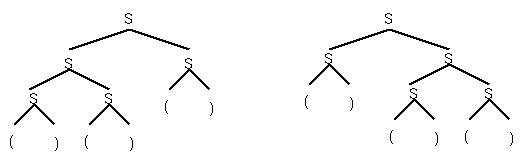
A grammar is ambiguous if some sentence has 2 distinct parse
trees.
The definition of a language does not require that it mean anything. Examples:
- set of all C assignments
- set of all C programs
- set of all identifiers
- set composed of even number of a's followed by a b
Functions of BNF
- distinguish between correct and incorrect programs
- syntactic analysis (parsing) uses rules to show how a string is derived from the grammar.
- assigns a structure to each string: provides semantic structure
Not unique, however, as many grammars may exist for same language - cannot completely define most languages features which involve
contextual dependence, e.g.:
- id used before defined
- id not declared twice
- number of subscripts must agree with declaration
YACC - can build a syntax analyzer quickly from the context free grammar.
Extended BNF (EBNF)
EBNF is (any) extension of BNF that provides a a shorthand notation for BNF rules. It adds no power to the syntax, only a shorthand way to write productions. It usually includes these features:| - Choice
( ) - Grouping
{ } * - Repetition - 0 or more
[ ... ] - Optional
Example: Identifier - a letter followed by 0 or more letters or
digits:
| I -> L { L | D }* | I -> L | L M |
| L -> a | b | ... | M -> C M | C |
| D -> 0 | 1 | ... | C -> L | D |
| L -> a | b | ... | |
| D -> 0 | 1 | ... |
Stages in translation
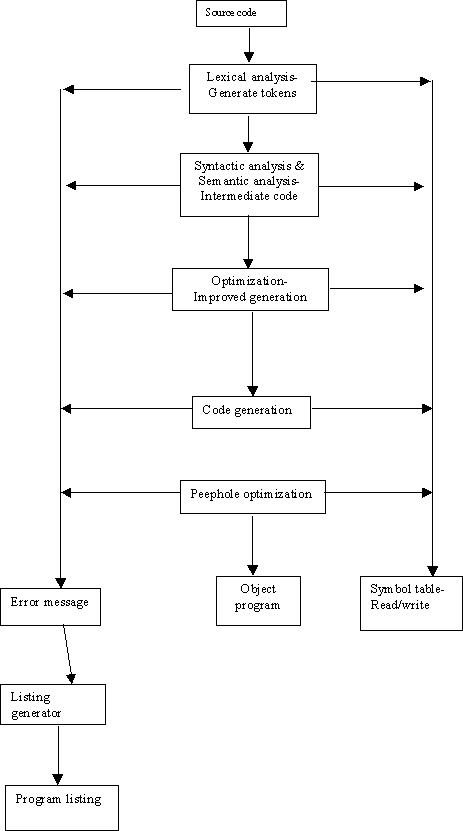
- lexical analysis (
 tokens)
Also called scanning
tokens)
Also called scanning
- Scanning divides the program into "tokens", which are the smallest meaningful units.
- You can design a parser to take characters instead of tokens as input, but it isn't pretty.
- The scanner may assign type tages to tokens, e.g., keywords, operators, identifers.
- The scanner also typically:
- removes comments
- produces a listing if desired
- saves text of strings, identifiers, numbers
- evaluates numeric constants (maybe)
- tags tokens with line numbers, for good diagnostics in later phases
- syntactic analysis ( parse tree)
Also called parsing- Parsing discovers the "context free" structure of the program. There are many different kinds of parsers. We will look at a Recursive Descent Parser next class if time permits.
- semantic analysis
- The compiler actually does what is called STATIC semantic anaylsis. That's the meaning that can be figured out at compile time.
- Static semantics includes things like
- insertion of implicit information
- error detection: recognize and produce informative messages
- making sure identifiers are declared before use
- type checking for assignments and operators
- checking types and numbers of parameters to subroutines
- making sure functions contain return statements
- making sure there are no repeats among switch statement labels
- Intermediate Code Generation
- After semantic analysis (if the program passes all checks), the compiler generates code in some intermediate form (IF).
- Intermediate forms are often chosen for machine independence, ease of optimization, or compactness (these are somewhat contradictory). They often resemble machine code for some imaginary idealized machine; e.g. a stack machine, or a machine with arbitrarily many registers.
- Many compilers actually move the code through more than one IF.
- Optimization
- Optimization takes an intermediate-code program and produces another one that does the same thing faster, or in less space.
- The optimization phase is optional.
- Code Generation
- The code generation phase produces assembly language or (sometime) relocatable machine language.
- Occasionally (especially in pedagogical environments, or scripting languages) load-and-go absolute machine language.
- Machine-Specific Optimization
- Certain machine-specific optimizations (use of special instructions or addressing modes, etc.) may be performed during or after target code generation.
- For example, register allocation and instruction scheduling happen after target code generation.
- Symbol table
- All phases rely on a symbol table that keeps track of all the identifiers in the program and what the compiler knows about them.
- entry for each identifier
- type of identifier: array, variable, subprogram anme, parameter
- type of values: integer, real
- This symbol table may be retained (in some form) for use by a debugger, even after compilation has completed.
Translators are grouped by number of passes required. Often two passes (decompose, generates object code).
An Example: ``Desk Calculator Language''
Definintion of the Language
- Informal description:
- All variables are integers.
- There are no declarations.
- The only statements are assignments, input, and output.
- Expressions get to use the four arithmetic operators and parentheses.
- Operators are left associative, with the usual precedence.
- There are no unary operators.
- Syntactic Description
- Tokens are:
[ Alphabet is the Union of the first three sets ] letter := { 'A',...,'Z' } digit := { '0', '1', ...,'9' } symbols:= { ':=', '+', '-', '*', '/', '(', ')', $$$ [means end of file] } id = letter ( letter | digit ) * [ except "read" and "write" ] literal = digit digit * - Grammar, in EBNF:
1. < pgm > - > < statement list > $$$ 2. < stmt list > - > < stmt list > < stmt > | epsilon 3. < stmt > - > id := < expr > | read < id > | write < expr > 4. < expr > - > < term > | < expr > < add op > < term > 5. < term > - > < factor | < term > < mult op > < factor > 6. < factor > - > ( < expr > ) | id | literal 7. < add op > - > + | - 8. < mult op > - > * | /
- By the way, there is an infinite number of grammars for any given language. This is just one.
Parse Tree from the Calculator Grammar
- Note how this grammar captures the notion of precedence:
- parse tree for 3 + 4 * 5 derived in class
- Consider what would have happened if rules 4 and 5 were:
< expr > - > < factor > | < expr > < op > < factor > - Also notice how it captures the notion of left associativity:
- parse tree for 10 - 4 - 3 derived in class
- Consider what would have happened if rule 4 was
< expr > - > < term > | < term > < add op > < expr > - This grammar is UNAMBIGUOUS. Consider what would have happened
if rules 4 and 5 were:
< expr > - > < factor > | < expr > < op > < expr >- two parse trees for A - B - C derived in class
Semantic Definition
Let's see what happens when we try to compile a simple program to print the sum and average of two numbers:
read A read B sum := A + B write sum write sum / 2There are 15 tokens in this program, which the scanner will pass on to the parser. The parser will discover the structure of the program and build a parse tree.
Because it is such a simple example, there is very little semantic analysis. We can check to make sure no variable is used before it is given a value, and that no variable is given a value that is never used.
For each symbol, we keep track of whether it has (a) no value, (b) an unused value, or (c) a used value in the symbol table. At the end of the program, we scan the whole symbol table to see if anything has an unused value, for example. If so, we print a warning message.
In addition to performing static checks, semantic analysis often simplifies the structure of the parse tree, getting rid of useless nodes, reducing the number of different kinds of nodes (e.g. expr v. term v. factor).
Intermediate code generation
For intermediate code generation, the compiler will again traverse the parse tree, making additional annotations. Annotations for code generation might (in a real compiler) include:
- sizes of variables
- locations of variables in memory
- whether values are known at compile time
- statistics on the range of case statement labels
- names and locations of temporary variables created to hold intermediate
- results of complicated computations
Our intermediate code might end up looking like this:
read pop A read pop B push A push B add pop sum push sum write push sum push 2 div writeThere are many other intermediate forms possible.
Target code generator
The target code generator will have to decide on how to use the resources of the target machine. Certain registers may be dedicated to special purposes, for example. The layout of main memory will have to be established.
For simplicity, let's assume:
- We use all but one of the data registers of the 680 to hold the top few elements of a stack that directly mirrors the P-code stack.
- We'll keep d0 free to be used to pass arguments to and from read and write.
- In addition, we'll give every variable a location in main memory.
Our code generator might produce the following in 680x0 essembly:
.data A: .long 0 B: .long 0 sum: .long 0 .text main: jsr read movl d0,d1 movl d1,A jsr read movl d0,d1 movl d1,B movl A,d1 movl B,d2 addl d1,d2 movl d1,sum movl sum,d1 movl d1,d0 jsr write movl sum,d1 movl #2,d2 divsl d1,d2 movl d1,d0 jsr writeCompilers without optimizers tend to produce code that is awful. In our case, much of the awfulness comes from doing a literal macro expansion of the stack-based intermediate code.
To do a good job with this language, we would want at least to apply a "peephole" optimizer to the assembly code. Better yet, pick a different intermediate language on which to do our optimizations.
- Tokens are: