To understand the implementation of linked lists and array lists
To analyze the efficiency of fundamental operations of lists and arrays
To implement the stack and queue data types
To implement a hash table and understand the efficiency of its operations
Implementing Linked Lists - The Node Class
We will implement a simplified, singly-linked list.
A linked list stores elements in a sequence of nodes.
A Node object stores an element and a reference to the next node.
private inner class
public instance variables
public class LinkedList
{
. . .
class Node
{
public Object data;
public Node next;
}
}
Implementing Linked Lists - The Node Class
A linked list object holds a reference to the first node:
each node holds a reference to the next node.
public class LinkedList
{
private Node first;
public LinkedList() { first = null; }
public Object getFirst()
{
if (first == null) { throw new NoSuchElementException(); }
return first.data;
}
}
Implementing Linked Lists - Adding and Removing the First Element
When adding or
removing the
first element, the
reference to the
first node must
be updated.
public class LinkedList
{
. . .
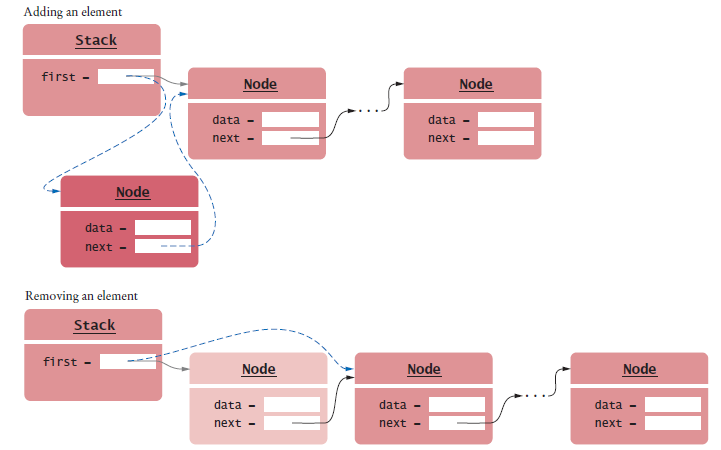
public void addFirst(Object element)
{
Node newNode = new Node();
newNode.data = element;
newNode.next = first;
first = newNode;
}
. . .
}
Implementing Linked Lists - Adding the First Element
Figure 1 Adding a Node to the Head of a Linked List
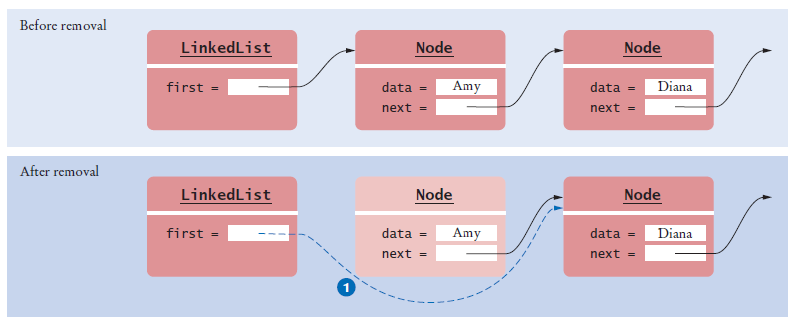
Implementing Linked Lists - Removing the First Element
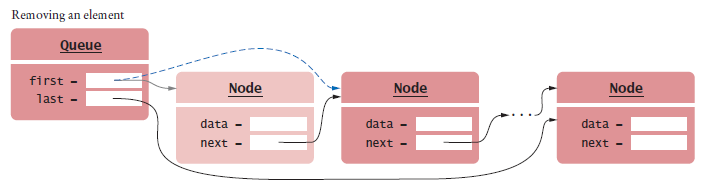
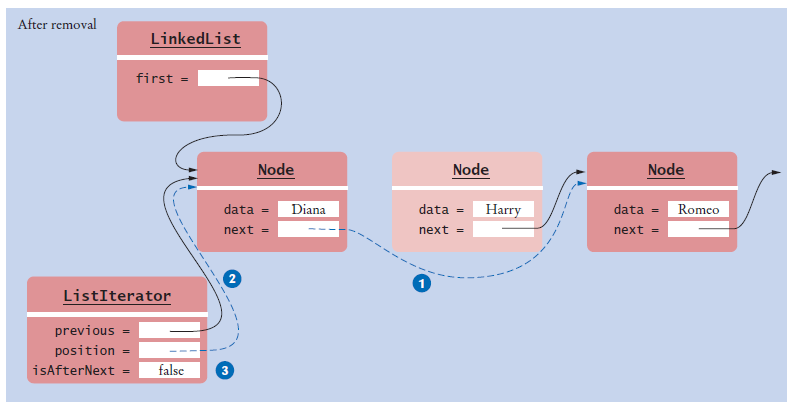
The data of the first node are saved and later returned as the method result.
The successor of the first node becomes the first node of the shorter list.
The old node is eventually recycled by the garbage collector.
public class LinkedList
{
. . .
public Object removeFirst()
{
if (first == null) { throw new NoSuchElementException(); }
Object element = first.data;
first = first.next;
return element;
}
. . .
}
Implementing Linked Lists - Removing the First Element
Figure 2 Removing the First Node from a LinkedList
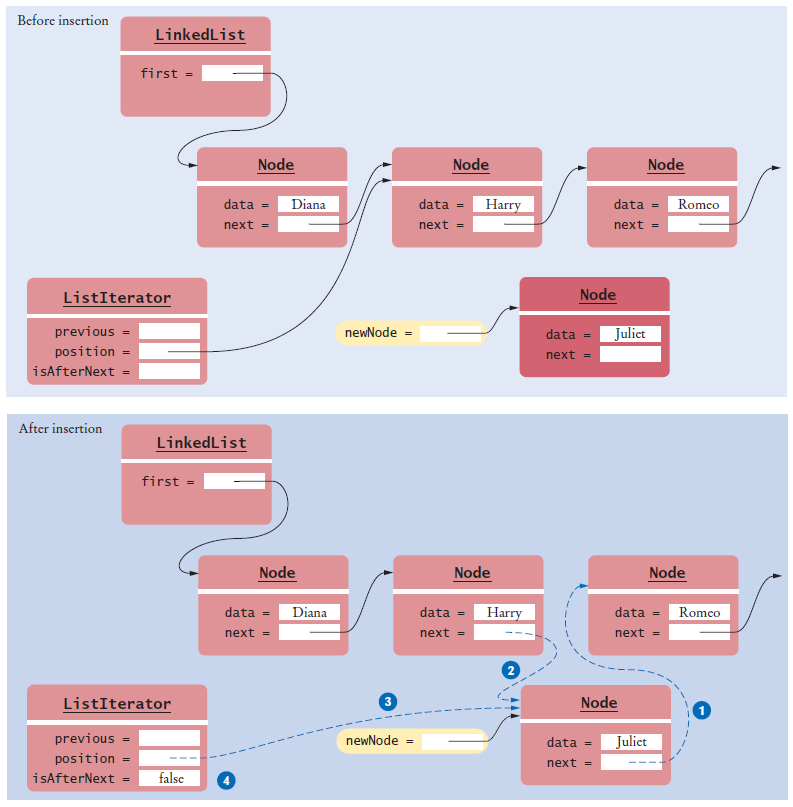
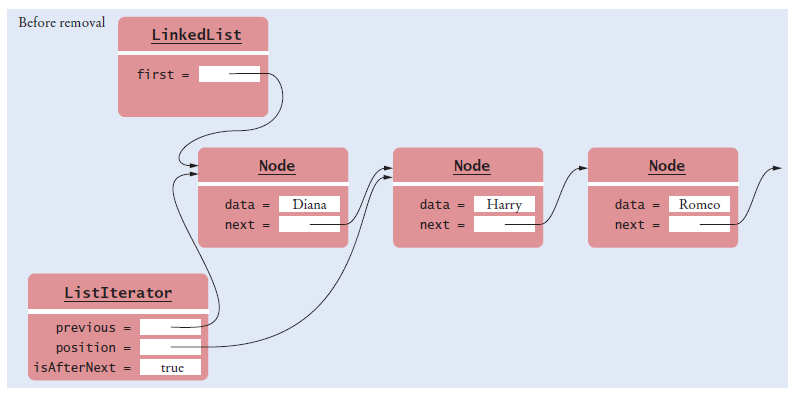
The Iterator Class
Our simplified ListIterator interface has methods: next, hasNext, remove, add, and set.
Our LinkedList class declares a private inner class LinkedListIterator.
Trace through the addFirst method when adding an element to an empty list.
Answer: When the list is empty, first is null. A new
Node is allocated. Its data instance variable is
set to the element that is being added. It’s next instance variable is set to null because first is
null. The first instance variable is set to the
new node. The result is a linked list of length 1.
Self Check 16.2
Conceptually, an iterator is located between two elements (see Figure 9 in Chapter
15). Does the position instance variable refer to the element to the left or the
element to the right?
Answer: It refers to the element to the left. You can see
that by tracing out the first call to next. It leaves
position to refer to the first node.
Self Check 16.3
Why does the add method have two separate cases?
Answer: If position is null, we must be at the head of the
list, and inserting an element requires updating
the first reference. If we are in the middle
of the list, the first reference
should not be
changed.
Self Check 16.4
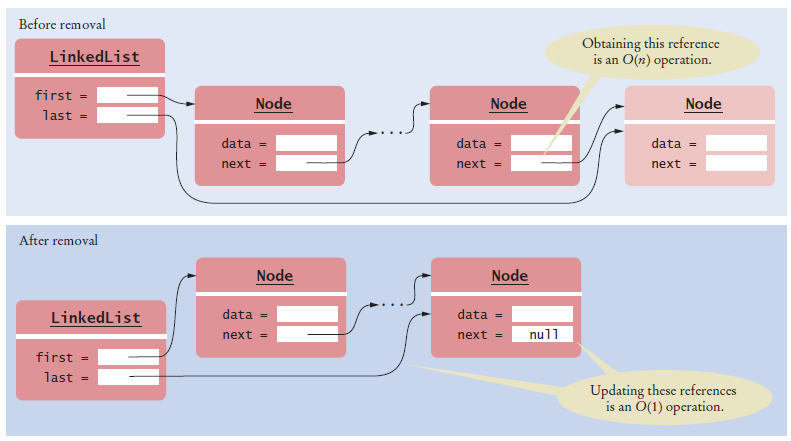
Assume that a last reference is added to the LinkedList class, as described in Section
16.1.8. How does the add method of the ListIterator need to change?
Answer: If an element is added after the last one, then
the last reference must be updated to point to
the new element. After position.next = newNode;
add if (position == last) { last = newNode; }
Self Check 16.5
Provide an implementation of an addLast method for the LinkedList class, assuming
that there is no last reference.
Answer:
public void addLast(Object element)
{
if (first == null) { addFirst(element); }
else
{
Node last = first;
while (last.next != null)
{
last = last.next;
}
last.next = new Node();
last.next.data = element;
}
}
Self Check 16.6
Expressed in big-Oh notation, what is the efficiency of the addFirst method of
the LinkedList class? What is the efficiency of the addLast method of Self Check 5?
Answer:O(1) and O(n).
Self Check 16.7
How much slower is the binary search algorithm for a linked list compared to
the linear search algorithm?
Answer: To locate the middle element takes n / 2 steps.
To locate the middle of the subinterval
to
the left or right takes another n / 4 steps. The
next lookup takes n / 8 steps. Thus, we expect
almost n steps to locate an element. At this
point, you are better off just making a linear
search that, on average, takes n / 2 steps.
Static Classes
Every object of an inner class has a reference to the outer class.
It can access the instance variables and methods of the outer class
If an inner class does not need to access the data of the outer class,
It does not need a reference
Declare it static to save the cost of the reference
Example: Declare the Node class of the LinkedList class as static:
public class LinkedList
{
. . .
static class Node
{
. . .
}
}
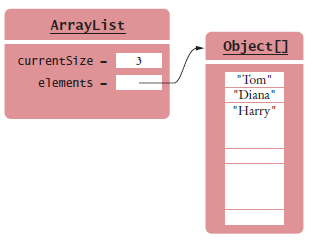
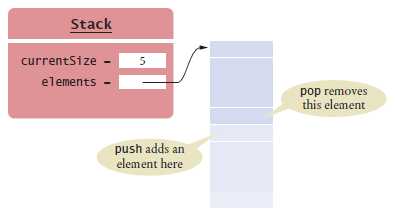
Implementing Array Lists
An array list maintains a reference to an array of elements.
The array is large enough to hold all elements in the collection.
When the array gets full, it is replaced by a larger one.
An array list has an instance field that stores the current number of elements.
Figure 7 An Array List Stores its Elements in an Array
Implementing Array Lists
Our ArrayList implementation will manage elements of type Object:
public class ArrayList
{
private Object[] elements;
private int currentSize;
public ArrayList()
{
final int INITIAL_SIZE = 10;
elements = new Object[INITIAL_SIZE];
currentSize = 0;
}
public int size() { return currentSize; }
. . .
}
Implementing Array Lists - Getting and Setting Elements
Providing get and set methods:
Check for valid positions
Access the internal array at the given position
Helper method to check bounds:
private void checkBounds(int n)
{
if (n < 0 || n >= currentSize)
{
throw new IndexOutOfBoundsException();
}
}
Implementing Array Lists - Getting and Setting Elements
The get method:
public Object get(int pos)
{
checkBounds(pos);
return element[pos];
}
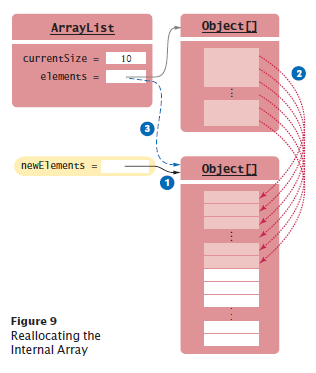
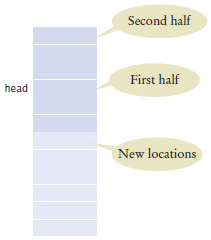
When an array list is completely
full, we must move the contents to
a larger array.
Growing the Internal Array
When the array is full:
Create a bigger array
Copy the elements to the new array
New array replaces old
Reallocation is O(n).
The growIfNecessary method:
private void growIfNecessary()
{
if (currentSize == elements.length)
{
Object[] newElements = new Object[2 * elements.length];
for (int i = 0; i < elements.length; i++)
{
newElements[i] = elements[i];
}
elements = newElements;
}
}
Growing the Internal Array
Growing the Internal Array
Reallocation seldom happens.
We amortize the cost of the reallocation over all the insertion or removals.
Adding or removing the last element in an array list takes amortized O(1) time.
Written O(1)+
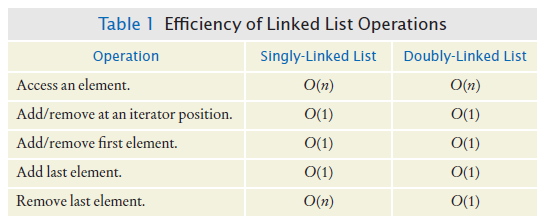
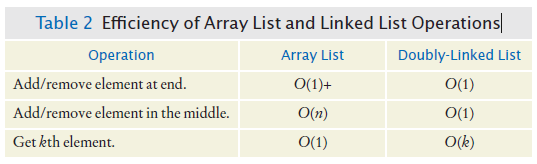
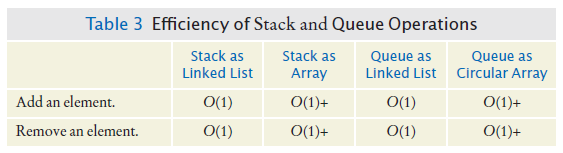
Efficiency of Array List and Linked List Operations
Self Check 16.8
Why is it much more expensive to get the kth element in a linked list than in an array list?
Answer: In a linked list, one must follow k links to get
to the kth elements. In an array list, one can
reach the kth element directly as elements[k].
Self Check 16.9
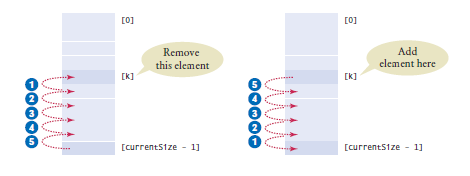
Why is it much more expensive to insert an element at the beginning of an array list than at the beginning of a linked list?
Answer: In a linked list, one merely updates references
to the first and second node––a constant cost that is independent of the number of elements
that follow. In an array list of size n, inserting
an element at the beginning requires us to
move all n elements.
Self Check 16.10
What is the efficiency of adding an element exactly in the middle of a linked list? An array list?
Answer: It is O(n) in both cases. In the case of the
linked list, it costs O(n) steps to move an iterator
to the middle.
Self Check 16.11
Suppose we insert an element at the beginning of an array list, and the internal
array must be grown to hold the new element. What is the efficiency of the add
operation in this situation?
Answer: It is still O(n). Reallocating the array is an O(n)
operation, and moving the array elements also
requires O(n) time.
Self Check 16.12
Using big-Oh notation, what is the cost of adding an element to an array list as the second-to-last element?
Answer:O(1)+. The cost of moving one element is
O(1), but every so often one has to pay for a
reallocation.
Implementing Stacks and Queues
Stacks and queues are abstract data types.
We specify how operations must behave.
We do not specify the implementation.
Many different implementations are possible.
Stacks as Linked Lists
A stack can be implemented as a sequence of nodes.
New elements are “pushed” to one end of the sequence, and they are “popped” from the same end.
Push and pop from the least expensive end - the front.
The push and pop operations are identical to the addFirst and removeFirst operations of the linked list.
Stacks as Linked Lists
Figure 10 Push and Pop for a Stack Implemented as a Linked List
Push and pop from the least expensive end - the back.
The array must grow when it gets full.
The push and pop operations are identical to the addLast and removeLast operations of an array list.
push and pop are O(1)+ operations.
Figure 11 A Stack Implemented as an Array
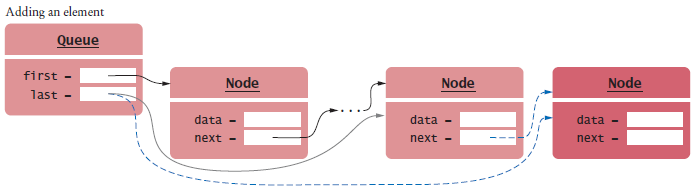
Queues as Linked Lists
A queue can be implemented as a linked list:
Add elements at the back
Remove elements at the front.
Keep a reference to last element
The add and remove operations are O(1) operations.
Queues as Linked Lists
Figure 12 A Queue Implemented as a Linked List
Queues as Circular Arrays
In a circular array, we wrap around to the beginning after the last element.
When removing elements of a circular array,
increment the index at which the head of the queue is locate
When the last element of the array is filled,
Wrap around and start storing at index 0
If elements have been removed there is room
else reallocate
All operations except reallocating are independent of the queue size
O(1)
Reallocation is amortized constant time
O(1)+
Queues as Circular Arrays
Self Check 16.13
Add a method peek to the Stack implementation in Section 16.3.1 that returns the
top of the stack without removing it.
Answer:
public Object peek()
{
if (first == null)
{
throw new NoSuchElementException();
}
return first.data;
}
Self Check 16.14
When implementing a stack as a sequence of nodes, why isn't it a good idea to
push and pop elements at the back end?
Answer:
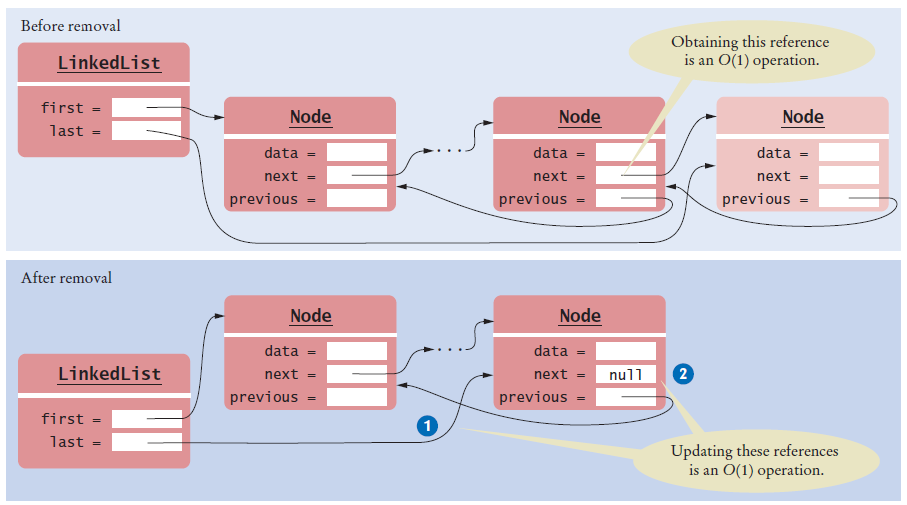
Removing an element from a singly-linked list is O(n).
Self Check 16.15
When implementing a stack as an array, why isn’t it a good idea to push and pop
elements at index 0?
Answer:
Adding and removing an element at index 0 is O(n).
Self Check 16.16
What is wrong with this implementation of the empty
method for the circular
array queue?
public boolean empty()
{
return head == 0 && tail == 0;
}
Answer:
The queue can be empty when the head and tail
are at a position other than zero. For example,
after the calls q.add(obj) and q.remove(), the
queue is empty, but head and tail are 1.
Self Check 16.17
What is wrong with this implementation of the empty method for the circular
array queue?
public boolean empty()
{
return head == tail;
}
Answer: Indeed, if the queue is empty, then the head
and tail are equal. But that situation also occurs
when the array is completely full.
Self Check 16.18
Have a look at the growIfNecessary method of the CircularArrayQueue class. Why
isn’t the loop simply:
for (int i = 0; i < elements.length; i++)
{
newElements[i] = elements[i];
}
Answer: Then the circular wrapping wouldn't work. If
we simply added new elements without reordering
the existing ones, the new array layout
would be
Implementing a Hash Table
In the Java library sets are implemented as hash sets and tree sets.
Hashing: place items into an array at an index determined from the element.
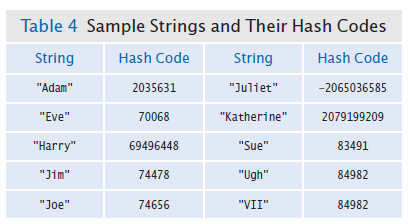
Hash code: an integer value that is computed from an object,
in such a way that different objects are likely to yield different hash codes.
Collision: when two or more distinct objects have the same hash code.
A good hash function minimizes collisions.
A hash table uses the hash code to determine where to store each element.
Implementing a Hash Table
Hash Tables
Hash table: An array that stores the set elements.
Hash code: used as an array index into a hash table.
Simplistic implementation
Very large array
Each object at its hashcode location
Simple to locate an element
But not practical
Figure 14 A Simplistic Implementation of a Hash Table
Hash Tables
Realistic implementation:
A reasonable size array.
Use the remainder operator to calculate the position.
int h = x.hashCode();
if (h < 0) { h = -h; }
position = h % arrayLength;
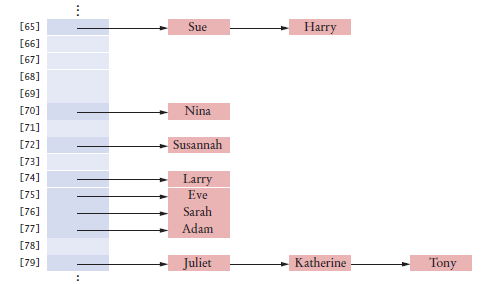
Use separate chaining to handle collisions:
All colliding elements are collected in a linked list of elements with the same position value
The lists are called buckets
Each entry of the hash table points to a sequence of nodes containing elements with the same hash code.
A hash table can be
implemented as an
array of buckets—
sequences of nodes
that hold elements
with the same
hash code.
Figure 15 A Hash Table with Buckets to Store Elements with the Same Hash Code
Hash Tables
Elements with the same hash code are placed in the same bucket.
Implementing a Hash Table - Finding an Element
Algorithm to find an element, obj
Compute the hash code and compress it.
gives an index h into the hash table.
Iterate through the elements of the bucket at position h.
Check element is equal to obj.
If a match is found among the elements of that bucket ,
obj is in the set.
Otherwise, it is not
If there are no or only
a few collision:
adding, locating,
and removing hash
table elements takes
O(1) time.
Adding and Removing Elements
Algorithm to add an element:
Compute the compressed hash code h.
Iterate through the elements of the bucket at position h.
For each element of the bucket, check whether it is equal to obj
If a match is found among the elements of that bucket, then exit.
Otherwise, add a node containing obj to the beginning of the node sequence.
If the load factor exceeds a fixed threshold, reallocate the table.
Load factor: a measure of how full the table is.
The number of elements in the table divided by the table length
Adding an element to a hash table is O(1)+
Adding and Removing Elements
Algorithm to remove an element:
Compute the hash code to find the bucket that should contain the object
Try to find the element
If it is present:
remove it
otherwise, do nothing
Shrink the table if it becomes to sparse
Removing an element from a hash table is O(1)+
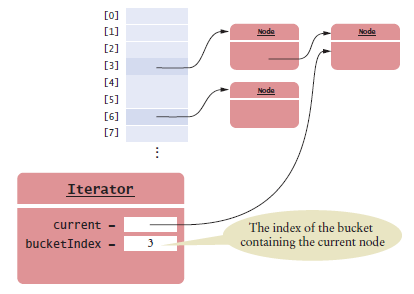
Iterating over a Hash Table
When iterator points to the middle of a node chain,
easy to get the next element
When the iterator is at the end of a node chain,
Skip over empty buckets
Advance the iterator to the first node of the first non-empty bucket
Iterator needs to store the bucket number and a reference to the current node in the node chain.
if (current != null && current.next != null)
{
current = current.next; // Move to next element in bucket
}
else // Move to next bucket
{
do
{
bucketIndex++;
if (bucketIndex == buckets.length)
{
throw new NoSuchElementException();
}
current = buckets[bucketIndex];
}
while (current == null);
}
Iterating over a Hash Table
Figure 16 An Iterator to a Hash Table
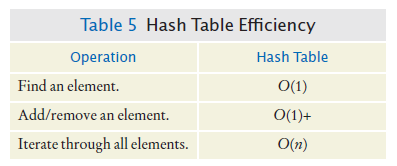
Hash Table Efficiency
The cost of iterating over all elements of a hash table:
Is proportional to the table length
Not the number of elements in the table
Shrink the table when the load factor gets too small.
Harry
Sue
Nina
Susannah
Larry
Eve
Sarah
Adam
Juliet
Katherine
Tony
Self Check 16.19
If a hash function returns 0 for all values, will the hash table work correctly?
Answer: Yes, the hash set will work correctly. All elements
will be inserted into a single bucket.
Self Check 16.20
If a hash table has size 1, will it work correctly?
Answer: Yes, but there will be a single bucket containing
all elements. Finding, adding, and removing
elements is O(n).
Self Check 16.21
Suppose you have two hash tables, each with n elements. To find the elements
that are in both tables, you iterate over the first table, and for each element,
check whether it is contained in the second table. What is the big-Oh efficiency
of this algorithm?
Answer: The iteration takes O(n) steps. Each step
makes an O(1) containment check. Therefore,
the total cost is O(n).
Self Check 16.22
In which order does the iterator visit the elements of the hash table?
Answer: Elements are visited by increasing (compressed)
hash code. This ordering will appear
random to users of the hash table.
Self Check 16.23
What does the hasNext method of the HashSetIterator do when it has reached the
end of a bucket?
Answer: It locates the next bucket in the bucket array
and points to its first element.
Self Check 16.24
Why doesn’t the iterator have an add method?
Answer: In a set, it doesn’t make sense to add an element
at a specific position.


 newNode.data = element;
newNode.next = first;
newNode.data = element;
newNode.next = first;  first = newNode;
first = newNode;  }
. . .
}
}
. . .
}
 }
. . .
}
}
. . .
}